Web Scraping API (LEGACY)
With our Web Scraping API, you can use the universal parameter as your target and supply any URL you want, which will return the HTML of the targeted URL.
You can integrate the API into your code, or test requests via your dashboard using scrapers .
There are two different solutions for Web Scraping API - Core and Advanced. Learn more about them here
universal
Retrieves results from any URL.
The following high-demand websites are supported by other Smartproxy products:
- Google: SERP Scraping API
- Amazon: eCommerce Scraping API
Targeting
google.comwith the Web Scraping API will not work.
Parameter | Type | Required | Description |
|---|---|---|---|
| string | ✅ | Website URL to scrape |
Authentication
Once you have an active Web subscription, you'll be able to check your generated proxy Username as well as see or regenerate a new Password in the API Authentication tab.
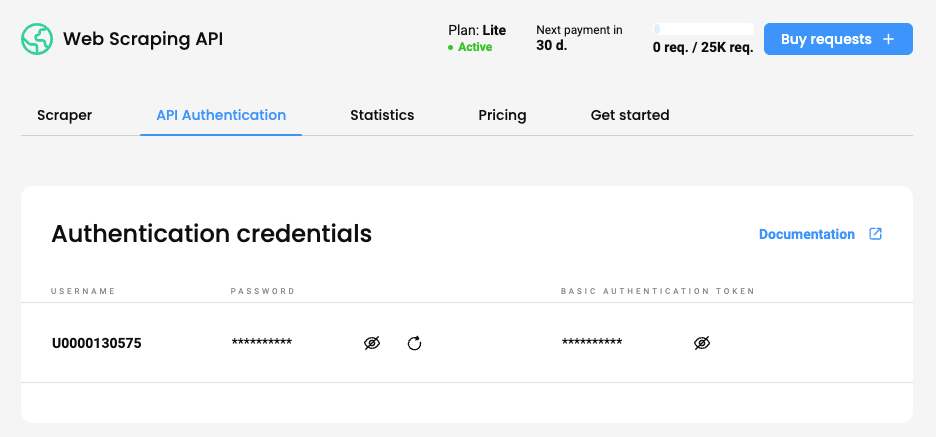
Smartproxy dashboard – the Web API Authentication section.
Target any websites with the universal parameter via code
You can use universal parameter as your target and supply any URL you want, which will return the HTML of the targeted URL.
Code examples for targeting ip.smartproxy.com website (with authorization details changed only):
import requests
url = "https://scraper-api.smartproxy.com/v2/scrape"
payload = {
"target": "universal",
"headless": "html",
"url": "https://ip.smartproxy.com"
}
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": "Base64 encoded user:pass"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)<?php
require_once('vendor/autoload.php');
$client = new \GuzzleHttp\Client();
$response = $client->request('POST', 'https://scraper-api.smartproxy.com/v2/scrape', [
'body' => '{"target":"universal","headless":"html","url":"https://ip.smartproxy.com"}',
'headers' => [
'Accept' => 'application/json',
'Authorization' => 'Base64 encoded user:pass',
'Content-Type' => 'application/json',
],
]);
echo $response->getBody();const options = {
method: 'POST',
headers: {
Accept: 'application/json',
'Content-Type': 'application/json',
Authorization: 'Base64 encoded user:pass'
},
body: JSON.stringify({target: 'universal', headless: 'html', url: 'https://ip.smartproxy.com'})
};
fetch('https://scraper-api.smartproxy.com/v2/scrape', options)
.then(response => response.json())
.then(response => console.log(response))
.catch(err => console.error(err));curl --request POST \
--url https://scraper-api.smartproxy.com/v2/scrape \
--header 'Accept: application/json' \
--header 'Authorization: Base64 encoded user:pass' \
--header 'Content-Type: application/json' \
--data '
{
"target": "universal",
"headless": "html",
"url": "https://ip.smartproxy.com"
}
'Result of the above code:

Sending requests via the dashboard using templates
You can try sending a request via your dashboard in the Scrapers section by creating a new project, inputting your URL, and customizing your desired parameters for the request.
- Click Create new project.
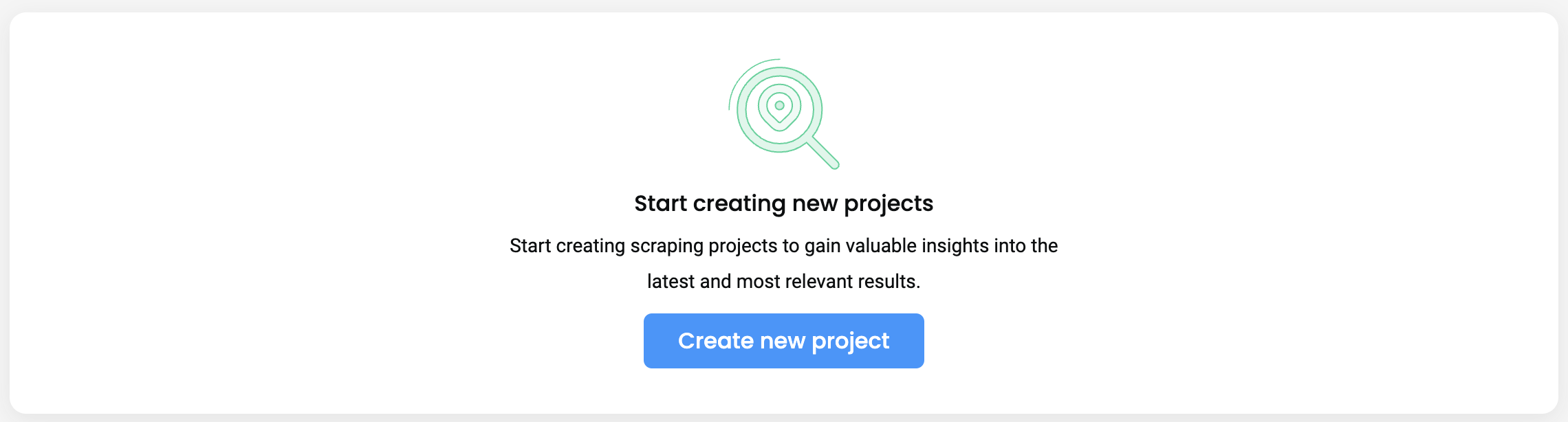
The Scrapers section – creating a new project.
- Open the dropdowns to specify your custom parameters.
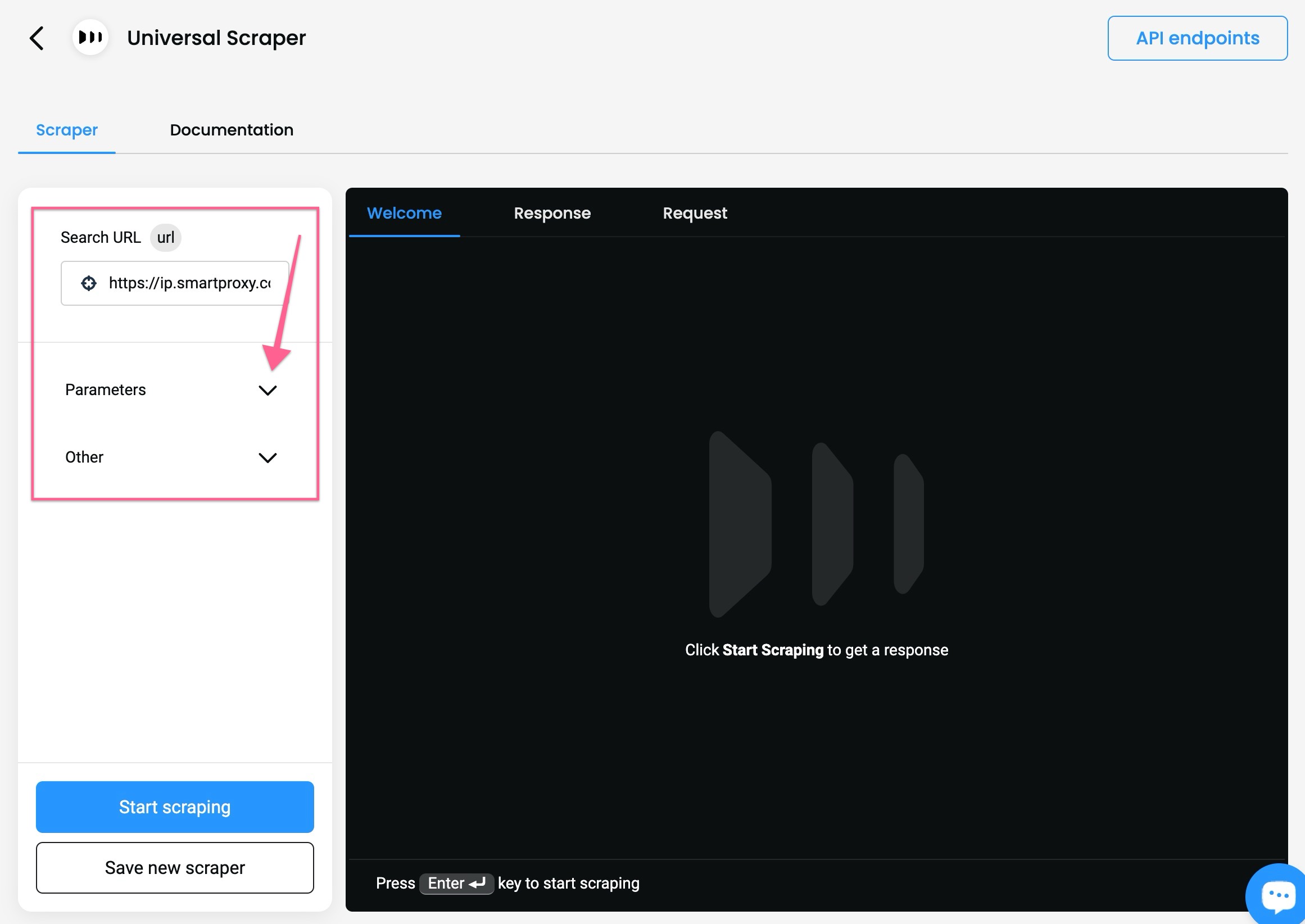
The Scrapers section – selecting parameters.
- You will also see the response in
HTMLand in the form of a Live Preview, as well as an example of acURL,Node, orPythonrequest if you select the Response or the Request tab respectively.
- You can Copy or Export the Response in
HTMLformat. - You can Copy the Request in each available language.
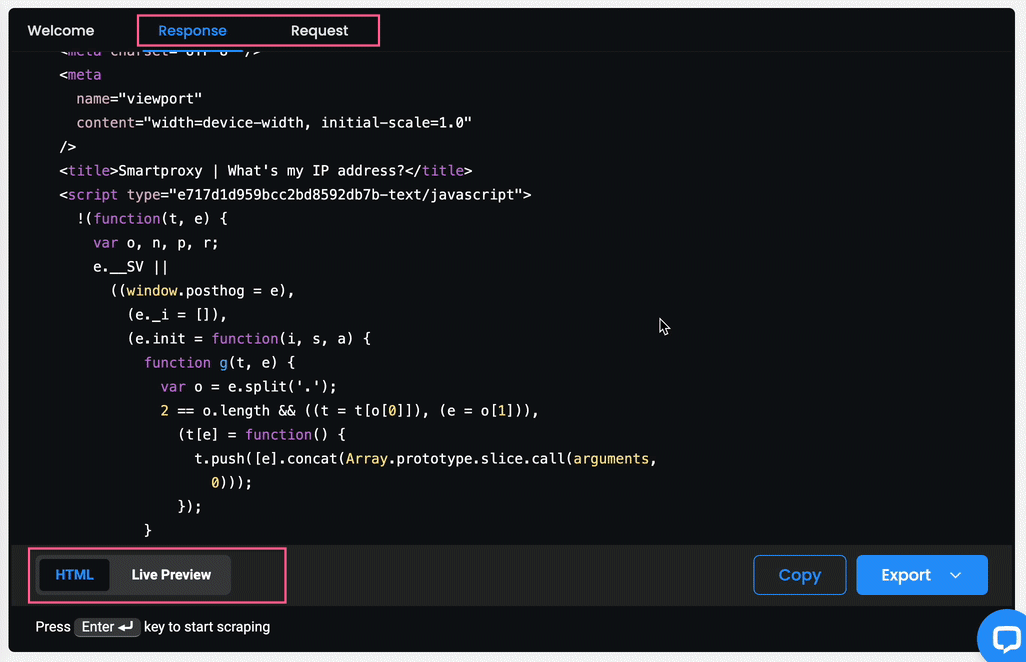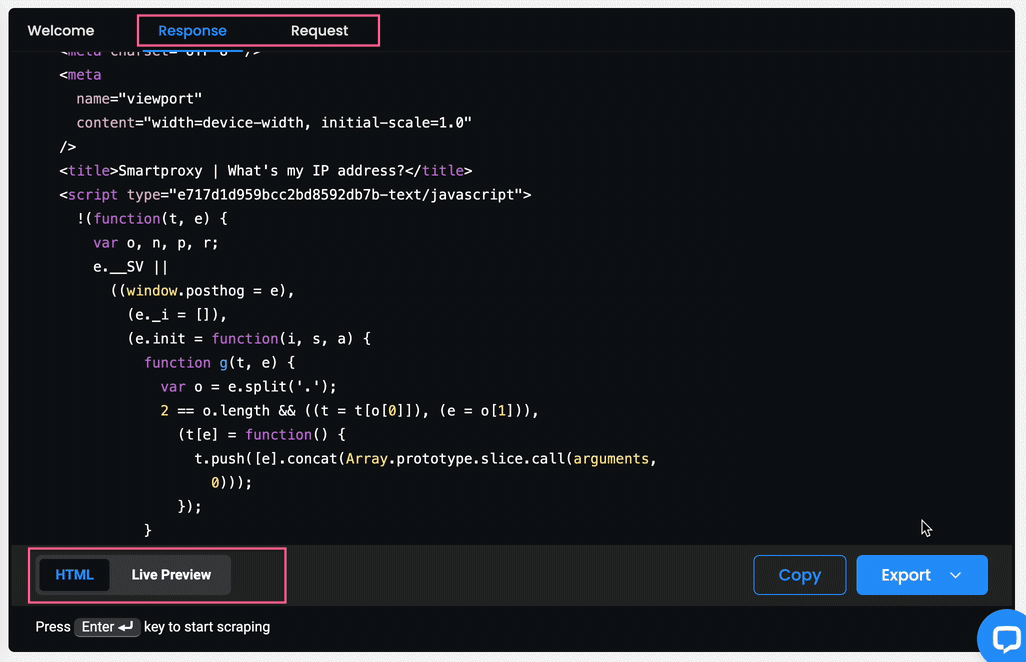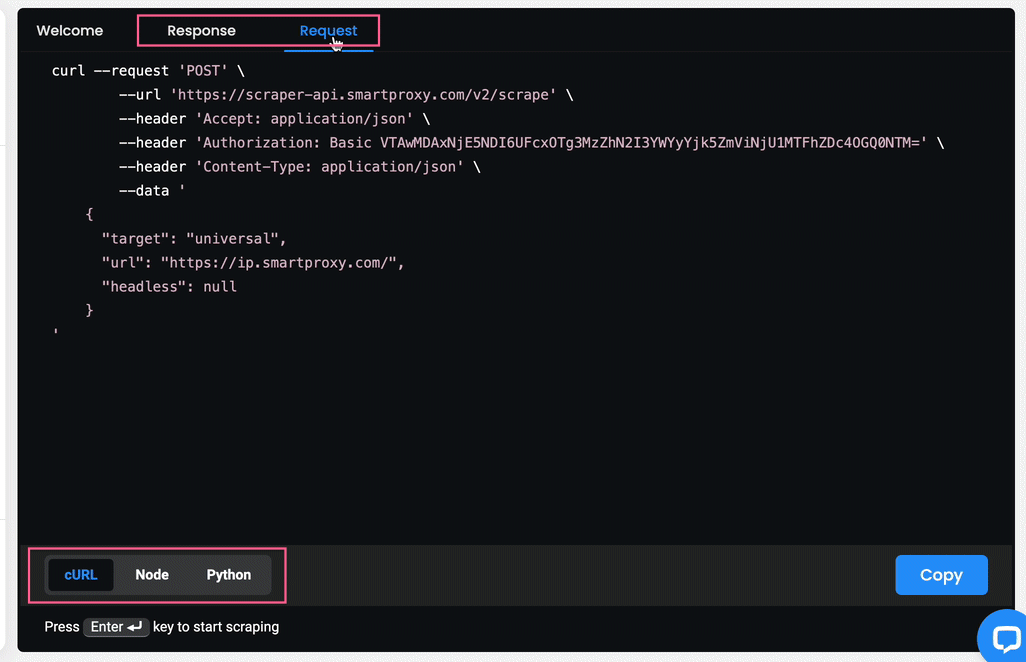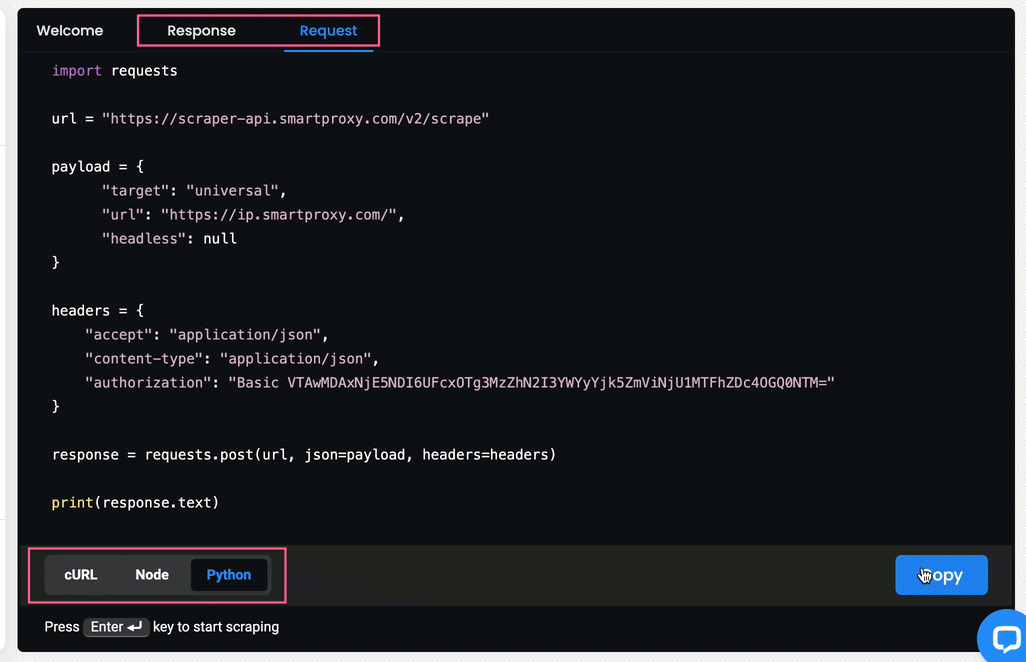
The Scrapers section – reviewing the results.
Saving & scheduling scraping templates
Once you select your parameters, you can save a specific template by clicking Save new scraper.
- Once saved, it will appear in the Scrapers section and you can click it to start working on it again.
- Click Update scraper to update the template.

The Scrapers section – saved templates.
To create a Schedule, click Schedule while a template is selected, and a right-side menu will pop up.
- You can specify the scheduling's frequency, delivery method (
emailorwebhook), and the format inJSON.
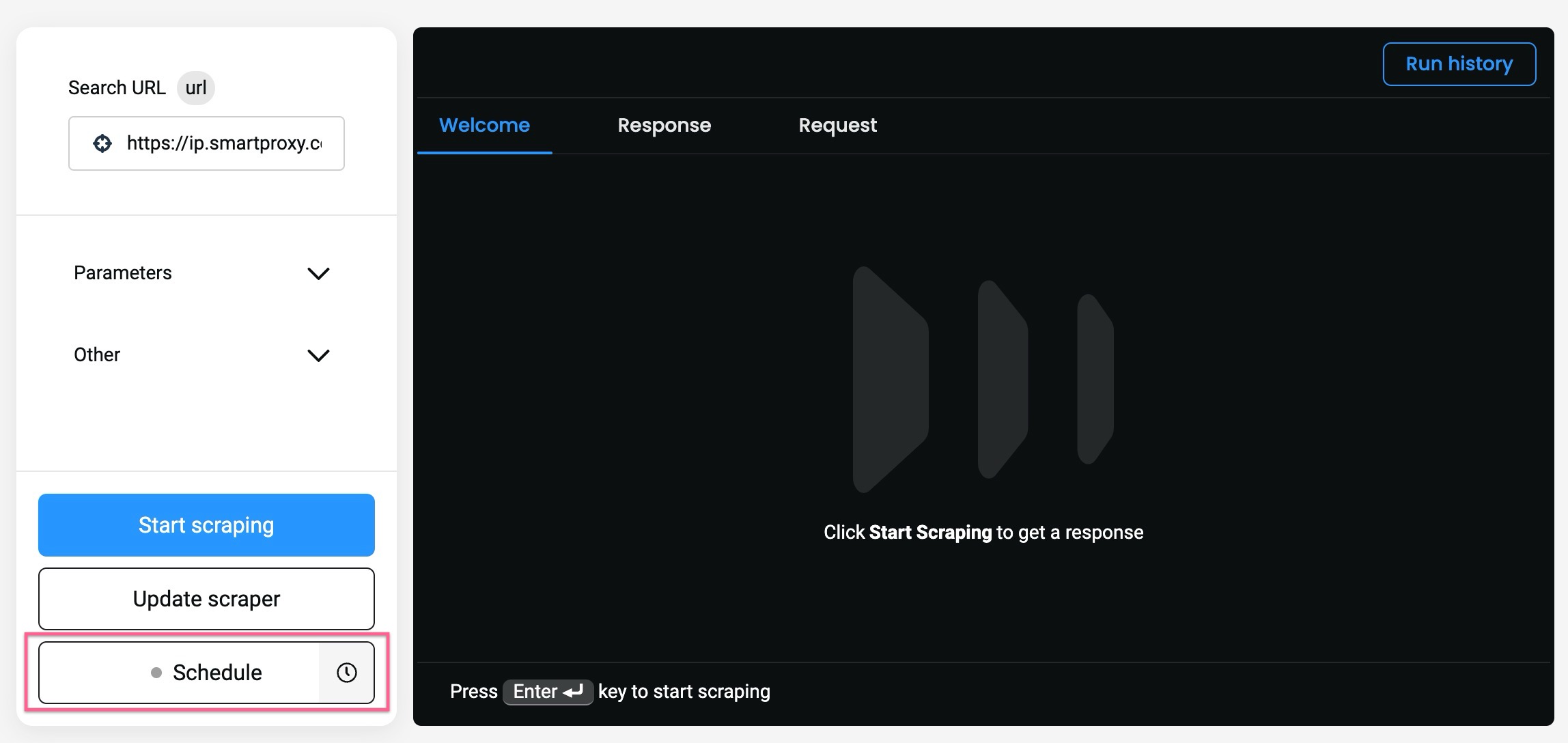
Creating a Schedule.
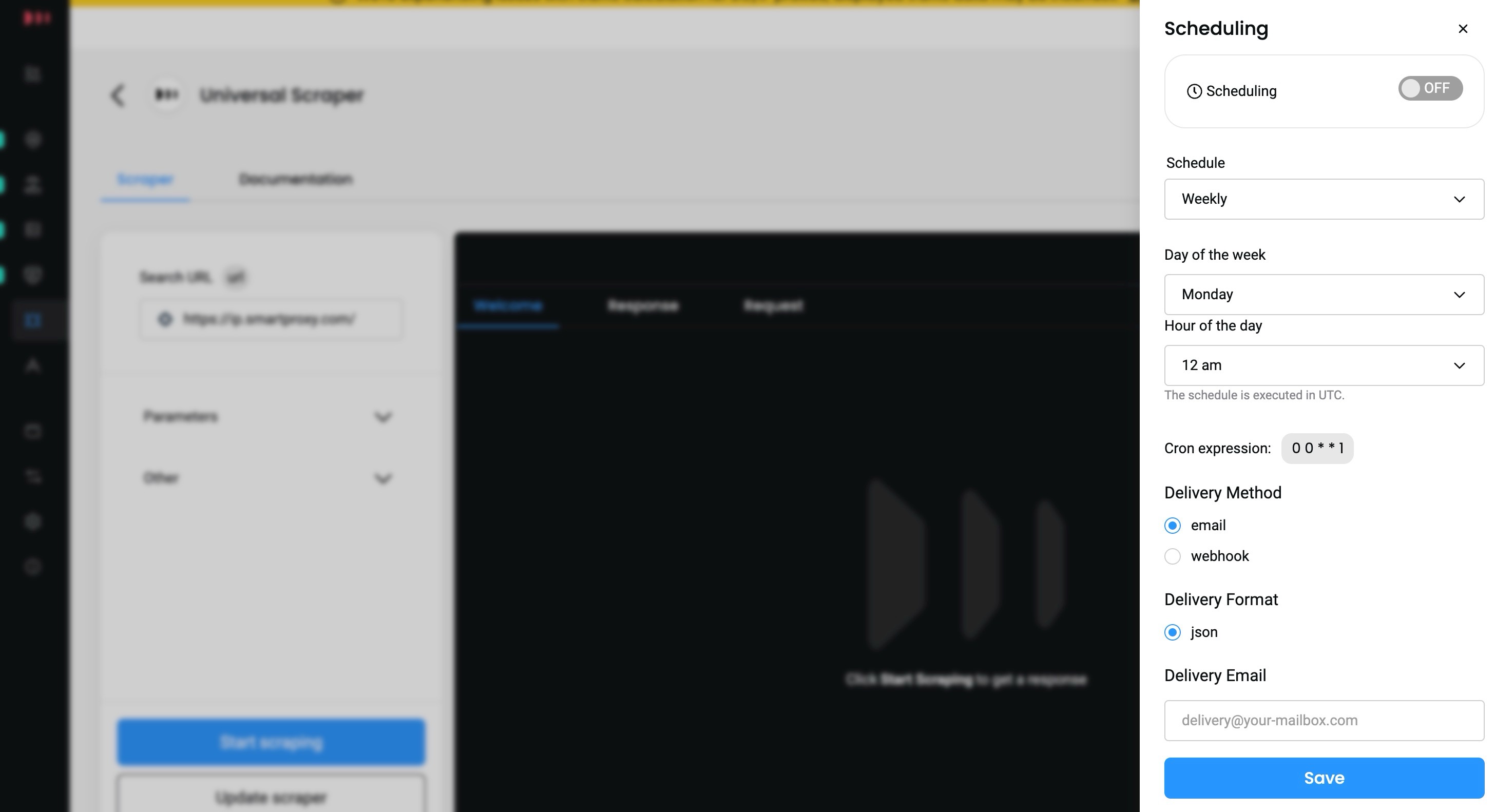
Managing the various aspects of scheduling.
Updated 10 days ago