Browser Actions (LEGACY)
Scraper APIs support performing a number of browser actions before retrieving a desired result.
Fetching a network request
If a website populates content by fetching a JSON object, you can scrape just the network request and thus avoid having to deal with HTML altogether. To do this, you can use the fetch_resource browser action as show below.
fetch_resourcecannot be combined with any other instructions and can only be used with separate requests.
For example, when loading yahoo.com and opening the Network tab, we can see an exp.json file being loaded:
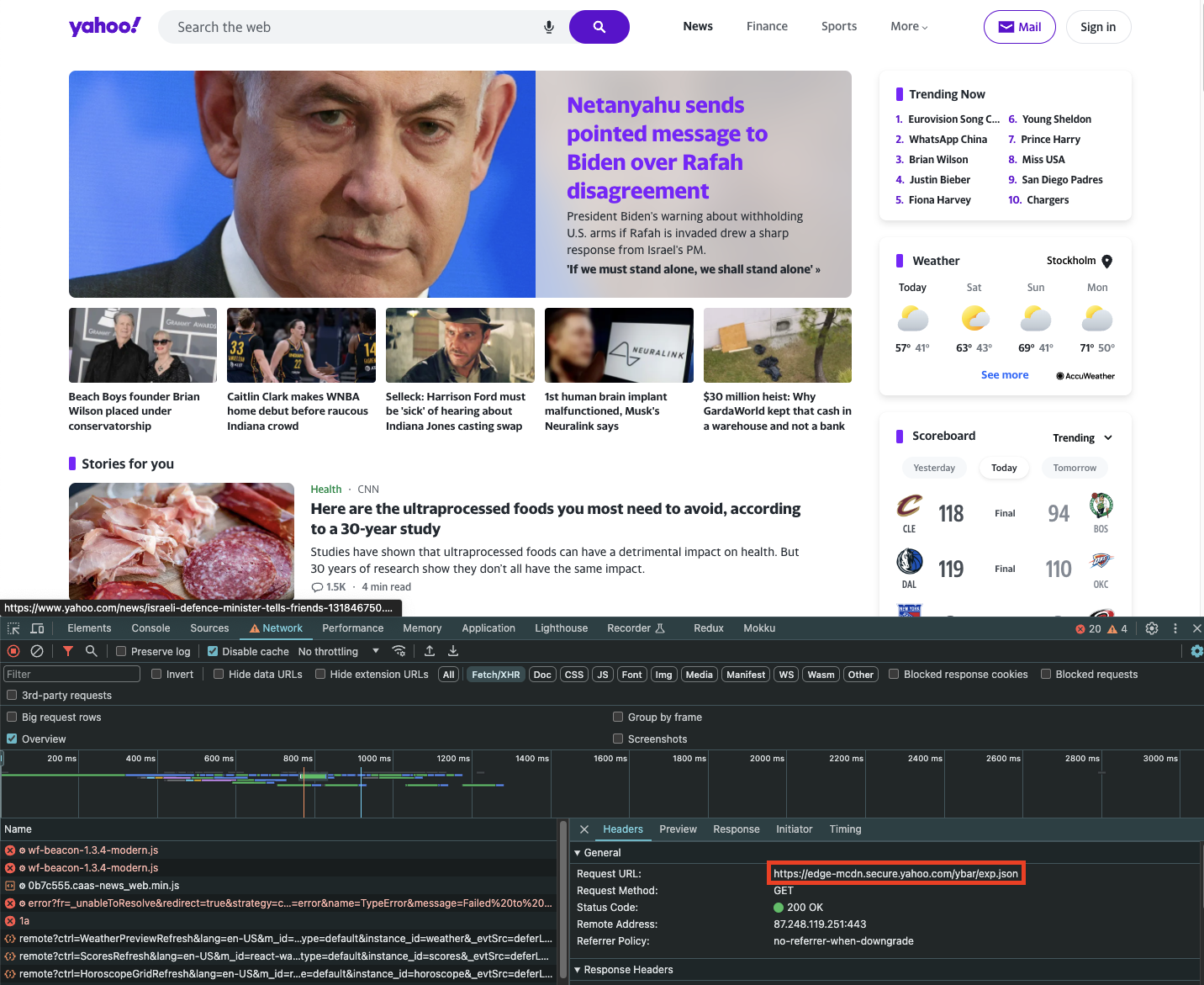
If you wish to scrape just the contents of this request, you can use the fetch_resource browser action. Note that filter is a regular expression that matches the filename:
{
"target": "universal",
"url": "https://www.yahoo.com/",
"browser_actions": [
{
"type": "fetch_resource",
"filter": "/ybar/exp"
}
]
}Results
{
"results": [
{
"content": "{\n \"expCount\":5,\n \"selection\":\"individual\",\n ... }",
"status_code": 200,
"url": "https://example.com/api/product/1",
"task_id": "7131940420107377665",
"created_at": "2023-11-19 09:46:41",
"updated_at": "2023-11-19 09:47:08"
}
]
}Actions
click
clickName | Arguments | Description |
|---|---|---|
| Selectors ["xpath", "css", "text"] | Clicks an element and wait a set count of seconds. |
Example:
{
"target": "universal",
"url": "https://www.yahoo.com/",
"browser_actions": [
{
"type": "click",
"selector": {
"type": "xpath",
"value": "//button"
}
}
]
}input
inputName | Arguments | Description |
|---|---|---|
| Selectors ["xpath", "css", "text"] | Enters a text into a selected element. |
scroll
scrollName | Arguments | Description |
|---|---|---|
| x: integer | Scrolls a set count of pixels. |
scroll_to_bottom
scroll_to_bottom| Name | Arguments | Description |
|---|---|---|
scroll_to_bottom | - | Scrolls to bottom for a set count of seconds. |
wait
wait| Name | Arguments | Description |
|---|---|---|
wait | wait_time_s | Waits a set count of seconds. |
Example:
{
"target": "universal",
"url": "https://news.ycombinator.com/",
"headless": "html",
"browser_actions": [
{
"type": "wait",
"wait_time_s": "20"
}
]
}wait_for_element
wait_for_elementName | Arguments | Description |
|---|---|---|
| Selectors ["xpath", "css", "text"] | Waits for element to load for a set count of seconds. |
fetch_resource
fetch_resource| Name | Arguments | Description |
|---|---|---|
fetch_resource | - | Fetches the first occurrence of a Fetch/XHR resource matching the set pattern. |
fetch_resource cannot be combined with any other instructions and should be used with separate requests.
fetch_resource cannot be combined with any other instructions and should be used with separate requests.General Arguments
Arguments available for all actions above
type
type| Name | Description |
|---|---|
type | Type of browser action used |
timeout_s
timeout_s| Name | Description |
|---|---|
timeout_s | How much time in seconds to wait at max until the execution of the action is terminated. |
wait_time_s
wait_time_s| Name | Description |
|---|---|
wait_time_s | How much time in seconds to use explicitly to execute the action. |
on_error
on_errorName | Description |
|---|---|
| Indicator what to do with actions in case they fail: |
Updated 10 days ago